Google har publisert TurboQuant, en ny komprimeringsalgoritme som krymper mellomlagringen i store språkmodeller med minst seks ganger, og det visstnok uten tap av nøyaktighet.
Oppdatert, 27. mars, 17:01:
Det spekuleres nå i at Googles AI-gjennombrudd kan være så stort at komponentpriskrisen, i det minste for RAM, er i ferd med å avta, eller i det minste å stabilisere seg. Det er nok for tidlig å si foreløpig, men i det minste er det 21 og 23 prosent tilbud på visse typer DDR5 32 GB RAM i norske nettbutikker. Det er færre tilbud på 64 GB-sett.
Det som gjør Google TurboQuant ekstra praktisk er at algoritmen er treningsfri og ikke bryr seg om LLM-modell. Det betyr at eksisterende modeller som ChatGPT, Llama, Mistral og Googles egne Gemma-modeller ikke behøver å trenes igjen, noe som er kostbart og koster energi
Annonse
Børsreaksjonen kom umiddelbart. Aksjer i SK Hynix, Samsung og Micron falt da investorer begynte å prise inn risikoen for at AI-industrien fremover vil trenge langt mindre minnekapasitet. Analytikere fra Wells Fargo påpekte at TurboQuant angriper kostnadskurven for RAM i AI-systemer direkte, men understreket samtidig at etterspørselen etter minnebrikker forblir sterk, og at kompresjonsalgoritmer historisk ikke har endret innkjøpsvolumene fundamentalt. Dette stemmer også: Micron f.eks. har økt litt.
Men hva er Google sin KV-cache som kan revolusjonere AI-verdenen?
Hver gang du skriver eller snakker med en AI-modell, lagres hele samtalen i et midlertidig minne kalt KV-mellomlagring (key-value cache). Dette fungerer som en huskeliste som gjør at modellen slipper å lese hele samtalehistorikken på nytt for hvert svar.
På en stor modell som Llama 70B kan denne cachen alene kreve opptil 40 GB GPU-minne under lange samtaler – det er ofte mer enn selve modellen.
Det betyr dessuten at en bruker i praksis kan oppta halvparten av kapasiteten til en GPU til rundt 250 000 kroner. Det høres noe dyrt ut. Derfor komprimerer stadig flere språkmodeller samtaledata, slik at de kan «huske» effektivt uten å sløse med energi på informasjon som allerede er behandlet.

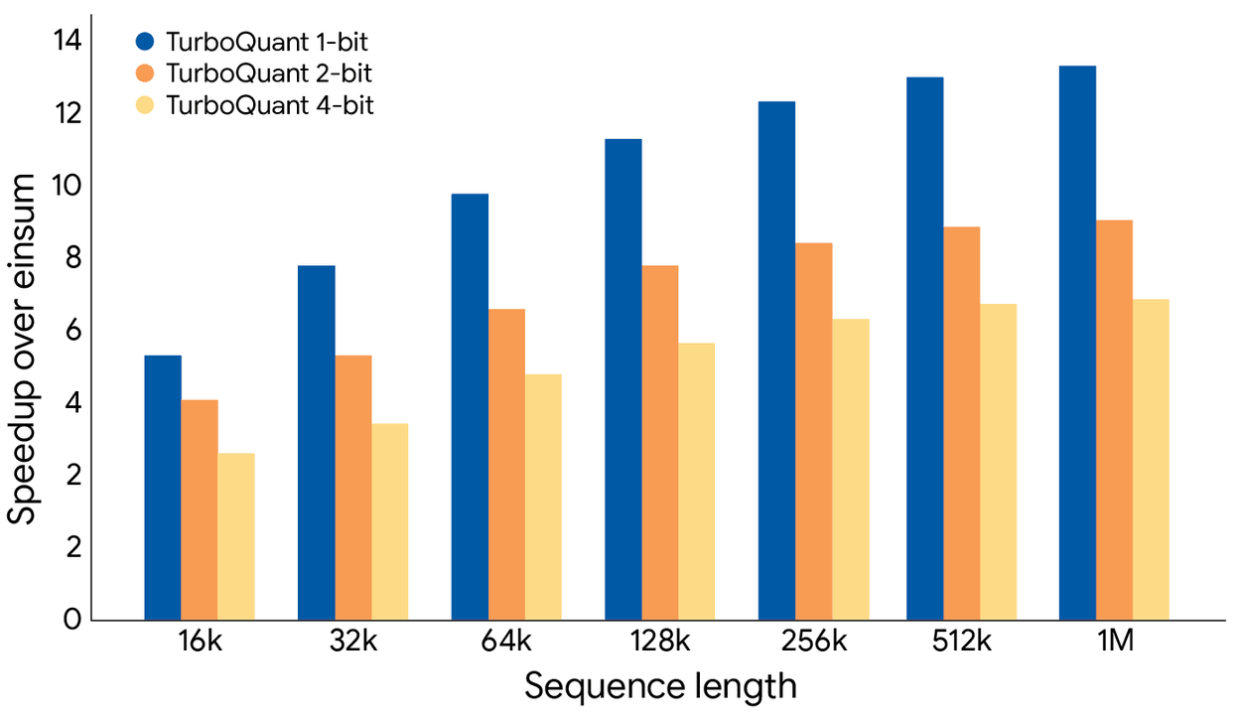

Seks ganger komprimering, null tap
TurboQuant komprimerer KV-mellomlagringen ned til tre bits per verdi, mot standard 16 bits. Google hevder algoritmen gjør dette uten nøyaktighetstap på tvers av samtlige testverktøy, og uten behov for omskolering eller finjustering av modellene.
På Nvidias H100 GPU-er leverer TurboQuant opptil åtte ganger raskere beregning av oppmerksomhetsvekter sammenlignet med ukomprimert 32-bits prosessering. Så effektive er modellene at RAM-selskapenes aksjekurs faktisk falt etter at selskapet annonserte nyheten.
Google har dessuten testet algoen på modellene Llama, Gemma og Mistral, og oppnår perfekte resultater på «needle-in-a-haystack»-tester, altså tester der der modellen må finne ett enkelt faktum gjemt i enorme tekstmengder.
Dette vil spare bransjen for mye RAM og energibruk
Seks ganger komprimering betyr i teorien at den samme maskinvaren kan håndtere seks ganger så mange samtidige samtaler, eller støtte seks ganger lengre kontekstvinduer, eller en kombinasjon av begge. TurboQuant fungerer også som en drop-in-erstatning og kan kombineres med eksisterende vektkomprimering av modeller.
Algoritmen er i tillegg testet på vektorsøk, teknologien som brukes til å finne semantisk lignende resultater i databaser med milliarder av oppføringer. Her overgår TurboQuant eksisterende metoder på hva den kan huske, ifølge Google.