Vi har nettopp hørt om OpenAI sine storslåtte planer om å utvikle egen maskinvare med blant annet Jony Ive som industridesigner for forbrukerprodukter igjen etter flere eksklusive merkevare-prosjekt.
Slik gjør de det
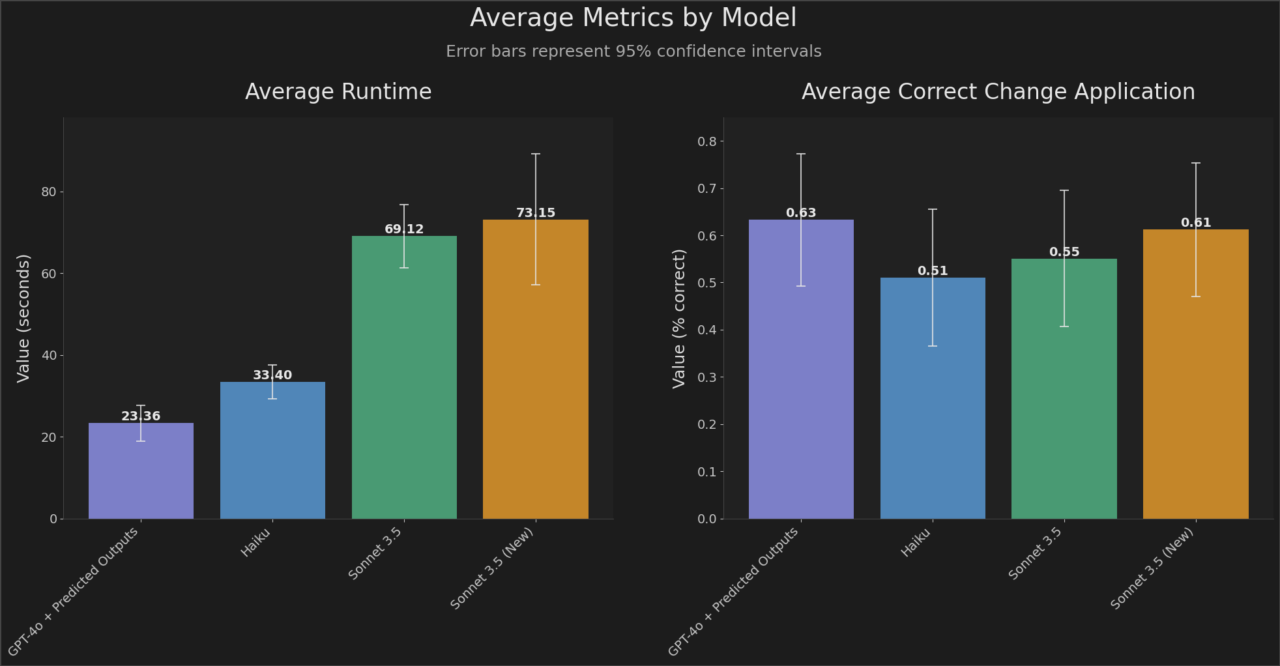
Men nå er det rett tilbake til algoritmer, for OpenAI har introdusert «Predicted Outputs,» som ifølge selskapet dramatisk kutter i etterslepet til de nye gpt-4o- gpt-4o-mini-modellene – dette ved å gi dem en referanse-streng.
Fortsatt ikke helt sikker på hva som menes? Ikke vi heller, så det var naturlig å spørre ChatGPT:
- Forutse svar: Hvis du vet noe av svaret fra før (som når du endrer kode litt), kan du gi modellen en forutsigelse som gjør at den svarer raskere.
- Bruk mindre modeller: Store modeller bruker lengre tid. Små modeller kan fungere like bra hvis du gir dem mer spesifikke instruksjoner.
- Færre tokens: Tokens er små enheter av tekst. Jo færre tokens som genereres, jo raskere går det. Be modellen gi korte svar eller kutte ut unødvendig tekst.
- Færre input tokens: Inndata (det du gir modellen) teller også. Kortere tekst i spørsmålene kan noen ganger redusere ventetiden, men effekten er ofte liten.
- Gjør færre forespørsler: Hver gang du spør modellen om noe, tar det tid. Hvis du har flere oppgaver, kan du be om alt i én forespørsel.
- Parallellisering: Hvis oppgavene ikke trenger å gjøres i rekkefølge, kan du be om dem samtidig. Dette sparer tid.
- Bruk ventetid klokt: Ventetid føles kortere hvis brukeren ser fremgang, som ved en lastelinje eller en spinning.
- Vurder alternativer til AI: Noen ganger kan enkle løsninger fungere bedre enn AI. For eksempel kan standardbeskjeder eller ferdige svar spare tid og være like bra.
Nå skjønner vi mer, og enda litt takket være kontekst fra Factory som samarbeider med OpenAI. Vi vet fremdeles ikke når dette lanseres, men følger utviklingen.